Knowing the intricacies of Multiply-Accumulate Operations (MACs) and Floating Point Operations (FLOPs) helps in developing neural network models that are not only accurate but also efficient and scalable. Building hardware-aware models ensures they are optimized for latency, power, and overall efficiency, making them suitable for real-world applications.
Floating Point Operations
FLOPs consists of all floating-point operations such as addition, subtraction, multiplication and division. In neural networks, FLOPs are measure of total computational workload required to process training or inference of a model.
Multiply-Accumulate Operations
MAC operation is multiplication of two numbers followed by an addition. This is the building blocks in layers of neural networks as each MAC operation is seen as a small step in calculating the final output of the layer
In neural networks, each MAC operation counts as two FLOPs (multiplication and addition).
MACs and FLOPs in Practice for Convolution
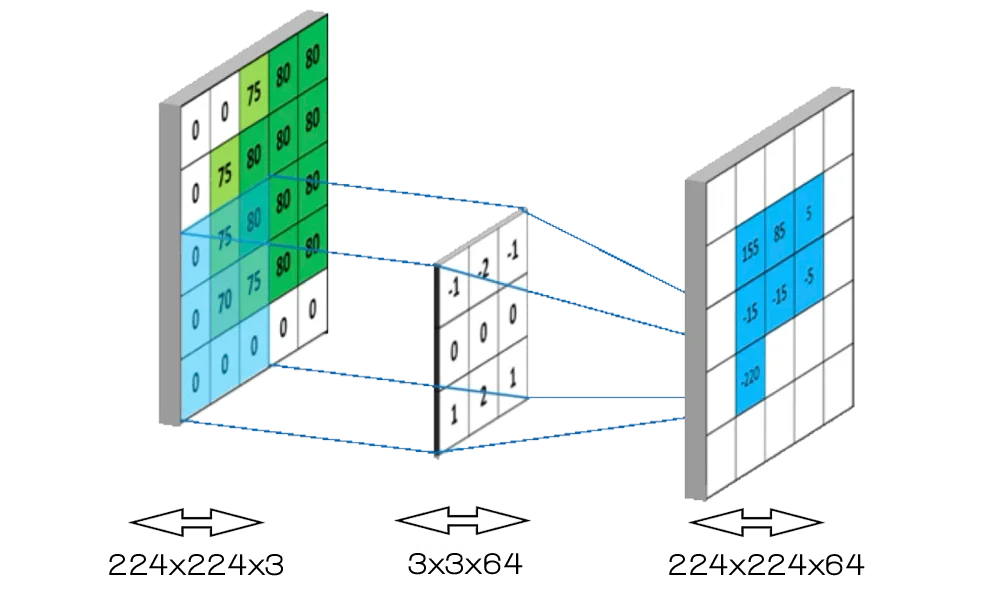
$$
\begin{aligned}
\text{MACs} &= \text{inp_channels} \times \text{kernel_w} \times \text{kernel_h} \times \text{out_w} \times \text{out_h} \times \text{out_channels} \
&= 3 \times 3 \times 3 \times 224 \times 224 \times 64 \
&= 86,!704,!128 \
\
\text{FLOPs} &= 2 \times \text{inp_channels} \times \text{kernel_w} \times \text{kernel_h} \times \text{out_w} \times \text{out_h} \times \text{out_channels} \
&= 2 \times 3 \times 3 \times 3 \times 224 \times 224 \times 64 \
&= 173,!408,!256
\end{aligned}
$$
Optimizing Neural Networks
Using FLOPs and MACs, we can estimate theoretical compute requirements of the model on a particular hardware, for example, latency and efficiency. To improve these, neural networks can be optimized by reducing the number of operations. Some ways are:
- Substitute layers that use less parameters (eg. Use separable conv layer)
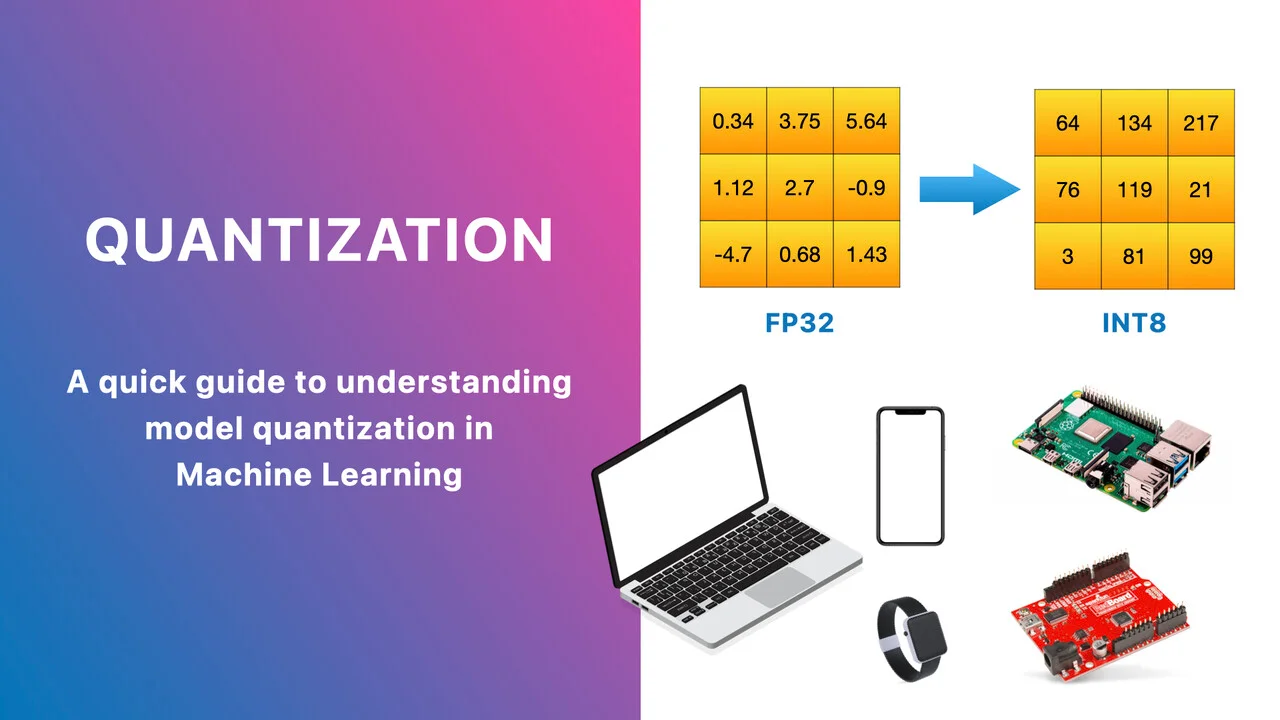
- Model Quantization
- Model Pruning
- Knowledge Distillation